Data Mining é uma das novidades da Ciência da Computação que veio para ficar. Com a geração de um volume cada vez maior de informação, é essencial tentar aproveitar o máximo possível desse investimento. Talvez a forma mais nobre de se utilizar esses vastos repositórios seja tentar descobrir se há algum conhecimento escondido neles. Um banco de dados de transações comerciais pode, por exemplo, conter diversos registros indicando produtos que são comprados em conjunto. Quando se descobre isso pode-se estabelecer estratégias para otimizar os resultados financeiros da empresa. Essa já é uma vantagem suficientemente importante para justificar todo o processo. Contudo, embora essa idéia básica seja facilmente compreensível, fica sempre uma dúvida sobre como um sistema é capaz de obter esse tipo de relação. No restante deste artigo vamos observar alguns conceitos que podem esclarecer essas dúvidas.
O Que É Data Mining?
Talvez a definição mais importante de Data Mining[1] tenha sido elaborada por Usama Fayyad (Fayyad et al. 1996):
"...o processo não-trivial de identificar, em dados, padrões válidos, novos, potencialmente úteis e ultimamente compreensíveis"
Esse processo vale-se de diversos algoritmos (muitos deles desenvolvidos recentemente) que processam os dados e encontram esses "padrões válidos, novos e valiosos". É preciso ressaltar um detalhe que costuma passar despercebido na literatura: embora os algoritmos atuais sejam capazes de descobrir padrões "válidos e novos", ainda não temos uma solução eficaz para determinar padrões valiosos. Por essa razão, Data Mining ainda requer uma interação muito forte com analistas humanos, que são, em última instância, os principais responsáveis pela determinação do valor dos padrões encontrados[2]. Além disso, a condução (direcionamento) da exploração de dados é também tarefa fundamentalmente confiada a analistas humanos, um aspecto que não pode ser desprezado em nenhum projeto que queira ser bem sucedido.
Os Passos do Data Mining
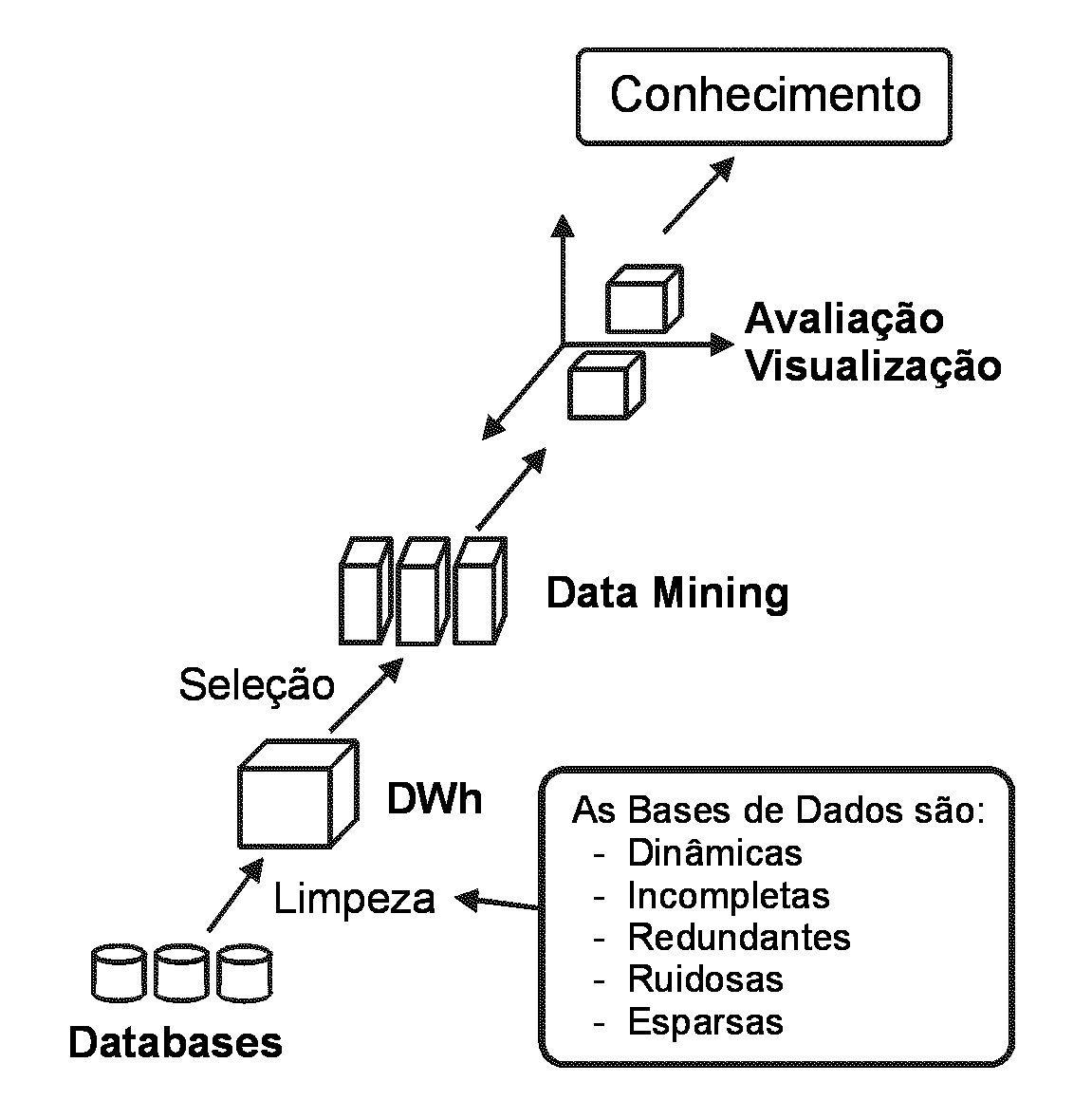
Mas é a partir deles que se pode selecionar algumas colunas para atravessarem o processo de mineração. Tipicamente, este processo não é o final da história: de forma interativa e frequentemente usando visualização gráfica, um analista refina e conduz o processo até que valiosos padrões apareçam. Observe que todo esse processo parece indicar uma hierarquia, algo que começa em instâncias elementares (embora volumosas) e terminam em um ponto relativamente concentrado, mas muito valioso.
Este é um dos conceitos importantes para nós neste artigo: encontrar padrões requer que os dados brutos sejam sistematicamente "simplificados" de forma a desconsiderar aquilo que é específico e privilegiar aquilo que é genérico. Faz-se isso porque não parece haver muito conhecimento a extrair de eventos isolados. Uma loja de sua rede que tenha vendido a um cliente em particular uma quantidade impressionante de um determinado produto em uma única data pode apenas significar que esse cliente em particular procurava grande quantidade desse produto naquele exato momento. Mas isso provavelmente não indica nenhuma tendência de mercado.
Em outras palavras, não há como explorar essa informação em particular para que no futuro a empresa lucre mais. Apenas com conhecimento genérico é que isto pode ser obtido. Por essa razão devemos, em Data Mining, controlar nossa vontade de "não perder dados". Para que o processo dê certo, é necessário sim desprezar os eventos particulares para só manter aquilo que é genérico.
Dos Dados à Sabedoria
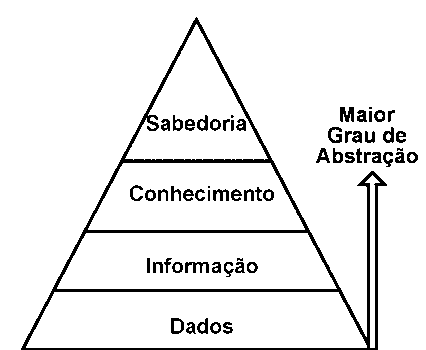
Assim como um organismo vivo, as empresas recebem informação do meio ambiente e também atuam sobre ele. Durante essas atividades, é necessário distinguir vários níveis de informação. O diagrama à esquerda apresenta a tradicional pirâmide da informação, onde se pode notar o natural aumento de abstração conforme subimos de nível.
Traduzido para uma empresa atual, esse diagrama fica como apresentado abaixo. O fundamental a se perceber neste diagrama é a sensível redução de volume que ocorre cada vez que subimos de nível. Essa redução de volume é uma natural consequência do processo de abstração.
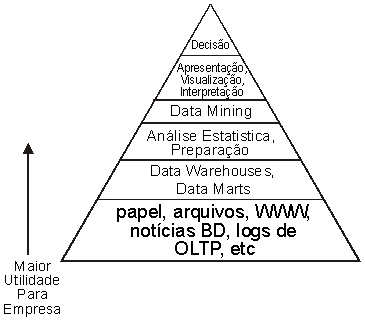
Abstrair, no sentido que usamos aqui, é representar uma informação através de correspondentes simbólicos e genéricos. Este ponto é importante: como acabamos de ver, para ser genérico, é necessário "perder" um pouco dos dados, para só conservar a essência da informação. O processo de Data Mining localiza padrões através da judiciosa aplicação de processos de generalização, algo que é conhecido como indução. Na próxima seção vamos ver este processo um pouco mais de perto.
Localizando Padrões
Padrões são unidades de informação que se repetem, ou então são sequências de informações que dispõe de uma estrutura que se repete. A tarefa de localizar padrões não é privilégio do Data Mining. Nosso cérebro utiliza-se de processos similares, pois muito do conhecimento que temos em nossas mentes é, de certa forma, um processo que depende da localização de padrões[3]. Por essa razão, muito do que se estuda sobre o cérebro humano também pode nos auxiliar a entender o que deve ser feito para localizar padrões. Mas o que é mesmo localizar padrões? O que é indução? Para exemplificar esses conceitos, proponho um breve exercício de uma indução de regras abstratas[4]. Nosso objetivo é tentar obter alguma expressão genérica para a seguinte sequência:
Sequência original: ABCXYABCZKABDKCABCTUABEWLABCWO
Observe atentamente essa sequência de letras e tente encontrar alguma coisa relevante. Veja algumas possibilidades:
Passo 1:
Passo 2:
"ABCXY"
"ABCZK"
"ABDKC"
"ABCTU"
"ABEWL"
"ABCWO"
"ABCZK"
"ABDKC"
"ABCTU"
"ABEWL"
"ABCWO"
Passo 3:
"ABC??" "ABD??" "ABE??" e "AB???",
onde '?' representa qualquer letraNo final desse processo, toda a sequência original foi substituída por regras genéricas indutivas[5] que simplificou (reduziu) a informação original a algumas expressões simples. Se você compreendeu esta explicação até aqui, então você acaba de conhecer um dos pontos essenciais do Data Mining: como se pode fazer para extrair certos padrões de dados brutos. Contudo, mais importante do que simplesmente obter essa redução (compressão) de informação, esse processo nos permite gerar formas de predizer futuras ocorrências de padrões. Este é exatamente o ponto onde este processo começa a mostrar o seu valor
Fazem-se agora induções, que geram algumas representações genéricas dessas unidades:Após determinarmos as sequências "ABC" e "AB", verificamos que elas segmentam o padrão original em diversas unidades independentes: A primeira etapa é perceber que existe uma sequência de letras que se repete bastante. Encontramos as sequências "AB" e "ABC" e observamos que elas ocorrem com frequência superior à das outras sequências. A literatura sobre o assunto trata com mais detalhes todos os passos necessários ao Data Mining. Veja, por exemplo, Groth (1998) e Han, Chen & Yu (1996). Para o escopo do que pretendemos neste artigo é suficiente apresentar os passos fundamentais de uma mineração bem sucedida (veja figura à direita). A partir de fontes de dados (bancos de dados, relatórios, logs de acesso, transações, etc) efetua-se uma limpeza (consistência, preenchimento de informações, remoção de ruído e redundâncias, etc). Disto nascem os repositórios organizados (Data Marts e Data Warehouses), que já são úteis de diversas maneiras.
site de pesquisa:http://www.intelliwise.com/reports/i2002.htm
ResponderExcluirsite de pesquisa: http://www.baixaki.com.br/tecnologia/1039-o que e-inteligencia-artificial-ai-.htm
ResponderExcluirHoje em dia, são várias as aplicações na vida real da Inteligência Artificial: jogos, programas de computador, aplicativos de segurança para sistemas informacionais, robótica (robôs auxiliares), dispositivos para reconhecimentos de escrita a mão e reconhecimento de voz, programas de diagnósticos médicos e muito mais.
ResponderExcluirBaseando-se em histórias fictícias como as citadas anteriormente, não é difícil imaginar o caos que poderá ser causado por seres de metal, com um enorme poder físico e de raciocínio, agindo independentemente da vontade humana. Guerras desleais, escravidão e até mesmo a extinção da humanidade estão no rol das conseqüências da IA.
Por outro lado, robôs inteligentes podem ser de grande utilidade na medicina, diminuindo o número de erros médicos, na exploração de outros planetas, no resgate de pessoas soterradas por escombros, além de sistemas inteligentes para resolver cálculos e realizar pesquisas que poderão encontrar cura de doenças.
Como pode ser notado, a Inteligência Artificial é um tema complexo e bastante controverso. São diversos os pontos a favor e contra e cada lado tem razão em suas afirmações. Cabe a nós esperar que, independente dos rumos que os estudos sobre IA tomem, eles sejam guiados pela ética e pelo bom senso.
Um Exemplo Prático
ResponderExcluirExistem muitas técnicas utilizadas pelo Data Mining, muitas delas desenvolvidas na disciplina Aprendizado de Máquina (Machine Learning, veja, por exemplo, Mitchell 1997). Vamos observar aqui apenas um pequeno exemplo prático do que podemos utilizar. Lembre-se das expressões abstratas genéricas que obtivemos na seção anterior. Uma dessas expressões nos diz que toda vez que encontramos a sequência "AB", podemos inferir que iremos encontrar mais três caracteres e isto completaria um "padrão". Nesta forma abstrata ainda pode ficar difícil de perceber a relevância deste resultado. Por isso vamos usar uma representação mais próxima da realidade.
Imagine que a letra 'A' esteja representando um item qualquer de um registro comercial. Por exemplo, a letra 'A' poderia significar "aquisição de pão" em uma transação de supermercado. A letra 'B' poderia, por exemplo, significar "aquisição de leite". A letra 'C' é um indicador de que o leite que foi adquirido é do tipo desnatado. É interessante notar que a obtenção de uma regra com as letras "AB" quer dizer, na prática, que toda vez que alguém comprou pão, também comprou leite. Esses dois atributos estão associados e isto foi revelado pelo processo de descoberta de padrões.
Esta associação já nos fará pensar em colocar "leite" e "pão" mais próximos um do outro no supermercado, pois assim estaríamos facilitando a aquisição conjunta desses dois produtos.